Direct Voxel Grid Optimization
Super-fast Convergence for Radiance Fields Reconstruction
CVPR 2022 (Oral)
- National Tsing Hua University
Results on custom casual capturing
A short guide to support custom forward-facing capturing and fly-through video rendering.
Results on real-world captured data
Features
- Speedup NeRF by replacing the MLP with the voxel grid.
- Simple scene representation:
- Volume densities:dense voxel grid (3D).
- View-dependent colors:dense feature grid (4D) + shallow MLP.
- Pytorch implementation.
- †Pytorch cuda extention built just-in-time for another 2--3x speedup.
- †O(N) realization for the distortion loss proposed by mip-nerf 360.
- The loss improves our training time and quality.
- We have released a self-contained pytorch package: torch_efficient_distloss.
- Consider a batch of 8192 rays X 256 points.
- GPU memory consumption: 6192MB => 96MB.
- Run times for 100 iters: 20 sec => 0.2sec.
- Supported datasets:
- Bounded inward-facing:
- †Unbounded inward-facing:
- †Foward-facing:LLFF.
† means new stuff after publication.
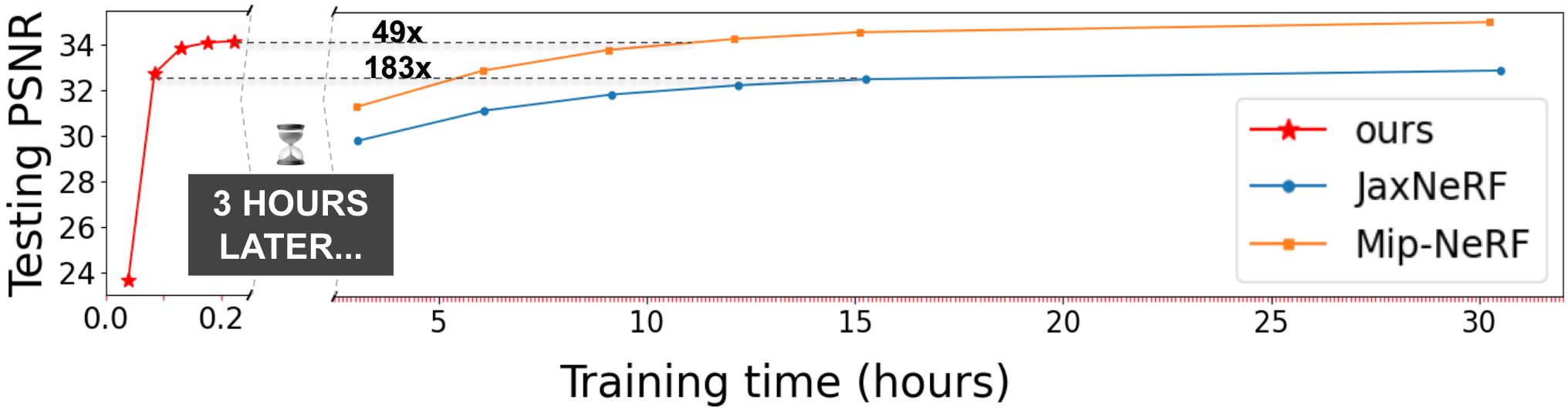
Motivation
- NeRF
- 😀 Excellent quality & flexibility.
- 😕 Very slow due to MLP queries.
- Replacing the MLP with voxel grid.
- 😀 Previous works[1,2,3] have shown a large inference time speedup with good quality.
- 😕 Limited to inference time. Pre-trained MLP is required.
- 🤔 How to train voxel grid directly from scratch?
Post-activation
Observation. To produce sharp surface, we have to activate density into alpha after interpolation.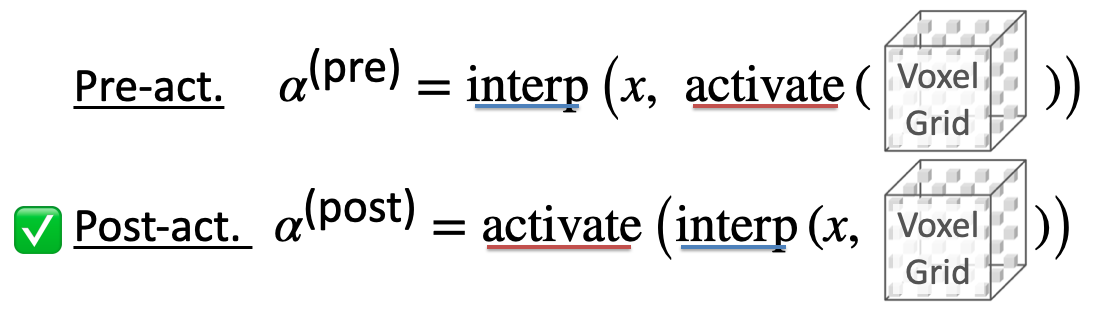
Proof. Post-activation can be arbitrarily close to a surface beyond linear. Detail in paper.
Toy example 1. Fitting a surface with a single 2D grid cell.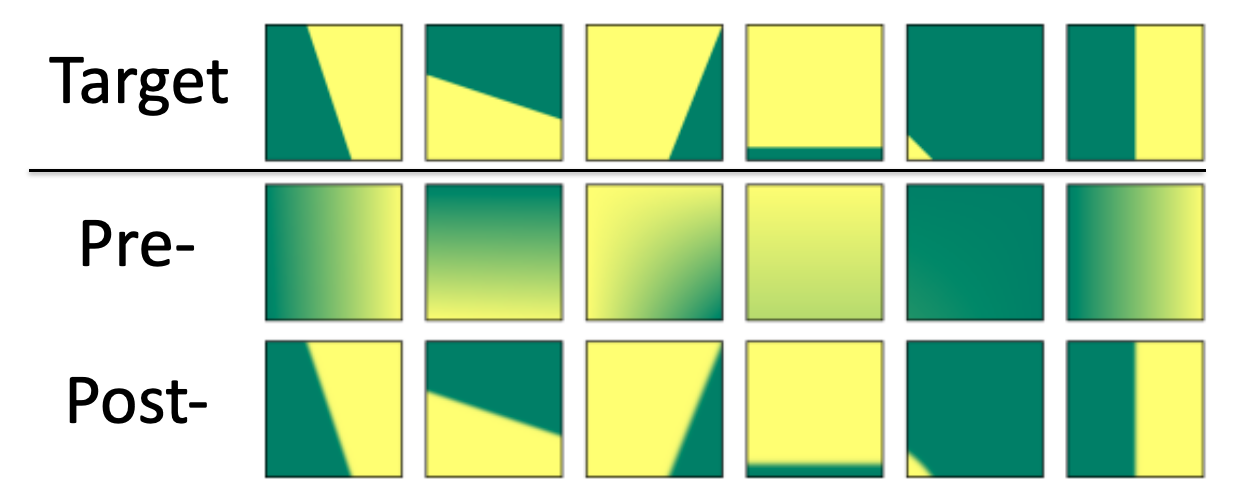
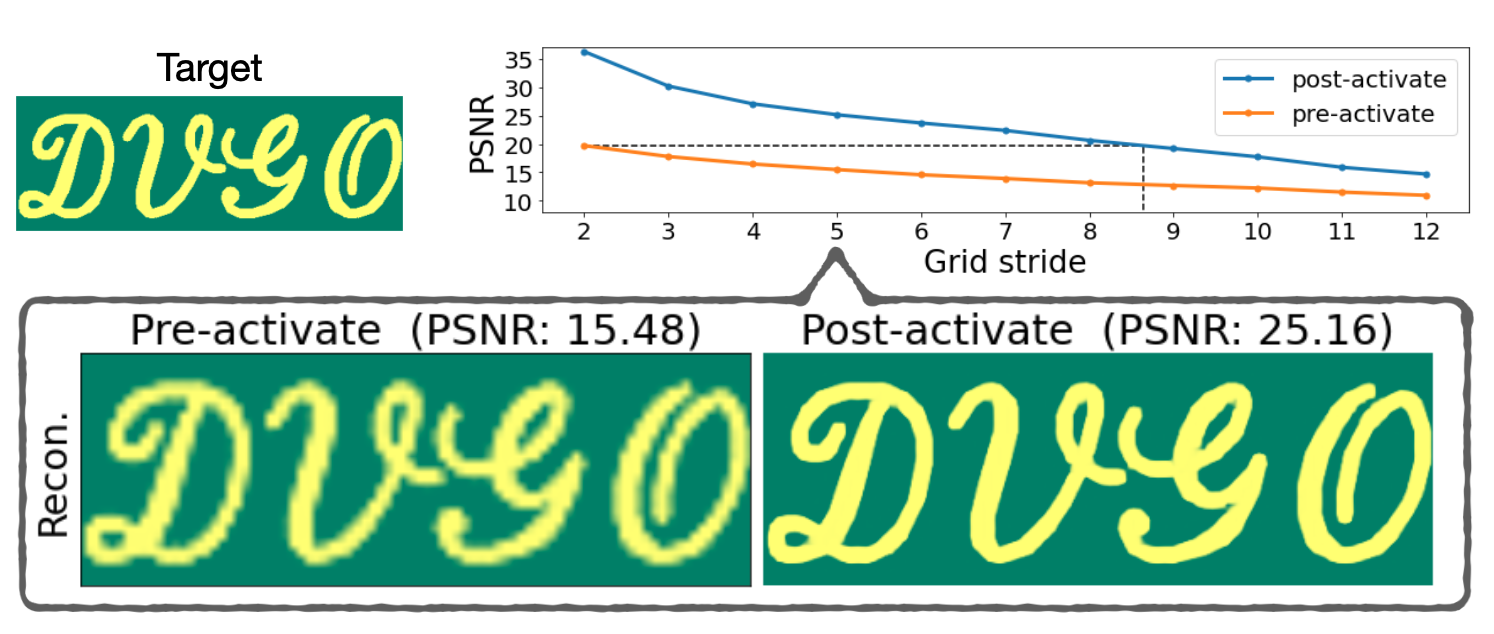
Ablation study. Up to 2.88 PSNR difference for novel-view synthesis.
Low-density initialization
Observation.
The initial alpha values (activated from the volume densities) should be close to 0.
We introduce a hyperparameter alpha-init to control it.
alpha-init should be small enough to achieve good quality and avoid floater.
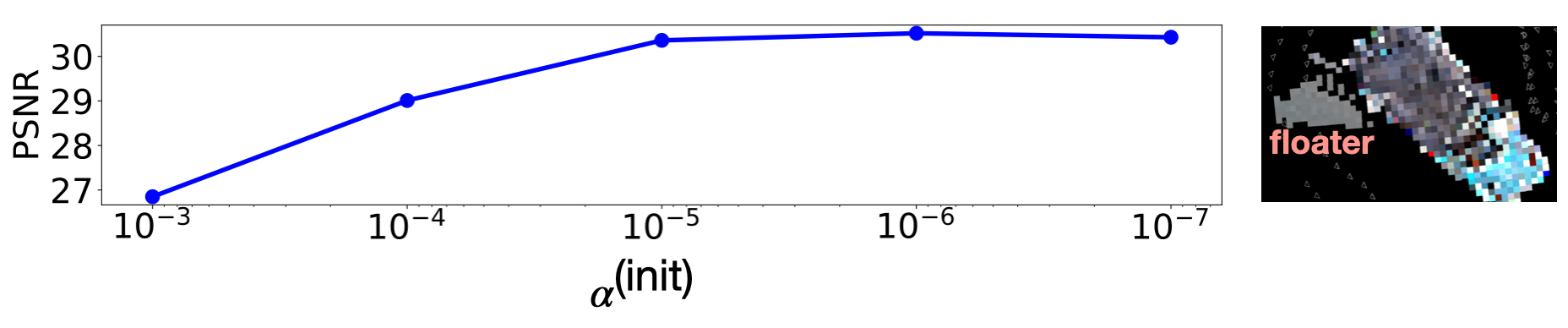
Caveat.
We empirically find that the qualities and the training times are sensitive to the alpha-init. We set alpha-init to 3 different values for bounded, unbounded inward-facing, and forward-facining datasets respectively. You may want to try a few different values for new datasets.
🤔 It seems that the explicit (grid-based) representation needs careful regularizations, while the implicit (MLP network) doesn't. We still don't know the root cause for this empirical finding at this moment.
Citation
@inproceedings{SunSC22,
author = {Cheng Sun and Min Sun and Hwann{-}Tzong Chen},
title = {Direct Voxel Grid Optimization: Super-fast Convergence for Radiance Fields Reconstruction},
booktitle = {CVPR},
year = {2022},
}Acknowledgements
This work was supported in part by the MOST grants 110-2634-F-001-009 and 110-2622-8-007-010-TE2 of Taiwan. We are grateful to National Center for High-performance Computing for providing computational resources and facilities.
This website is in part based on a template of Michaël Gharbi.